Python将同一文件夹下大量txt存入一个Excel文件(xlwt\openpyxl)以及批量合并txt的超快方法 |
您所在的位置:网站首页 › python 导入文本 › Python将同一文件夹下大量txt存入一个Excel文件(xlwt\openpyxl)以及批量合并txt的超快方法 |
Python将同一文件夹下大量txt存入一个Excel文件(xlwt\openpyxl)以及批量合并txt的超快方法
|
文章目录
数据说明用xlrd和xlwt读写excel使用openpyxl库读写excel最简单的批量合并txt(适用海量数据)win10批量合并办法:
数据说明
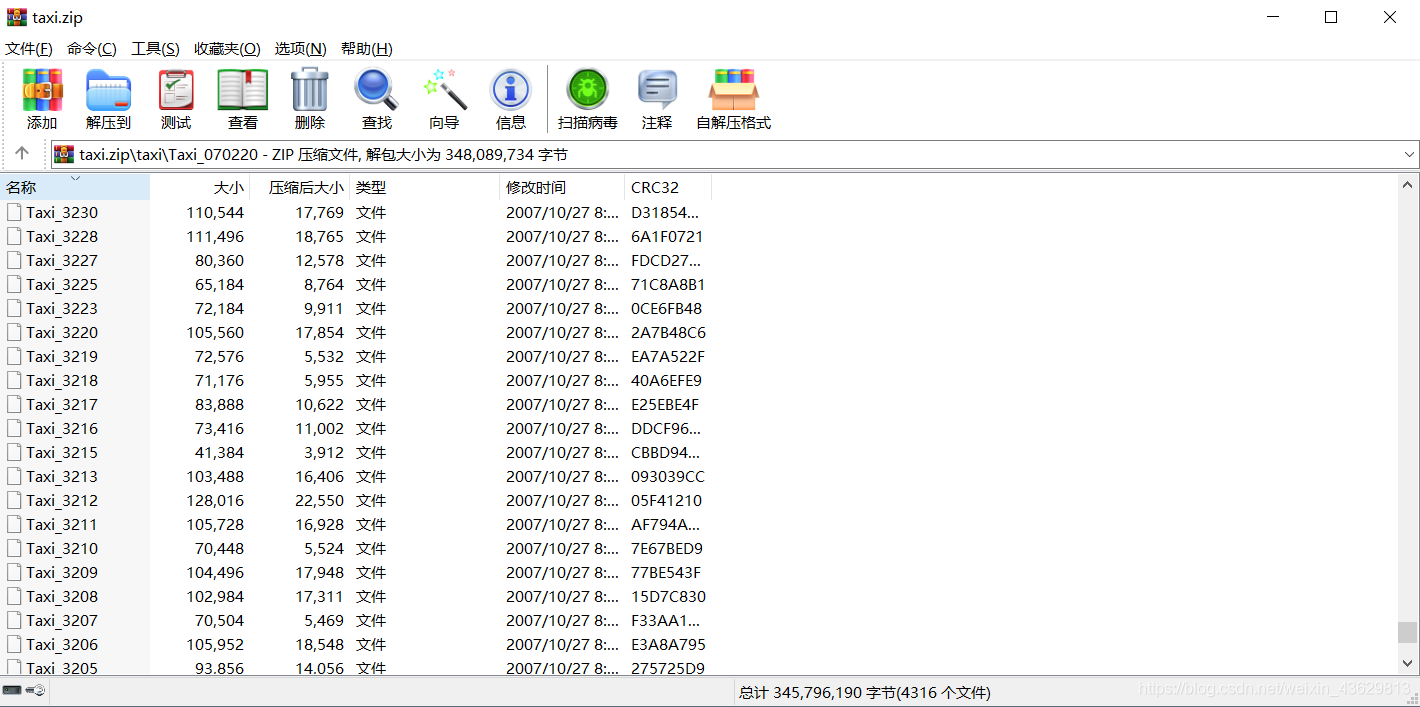
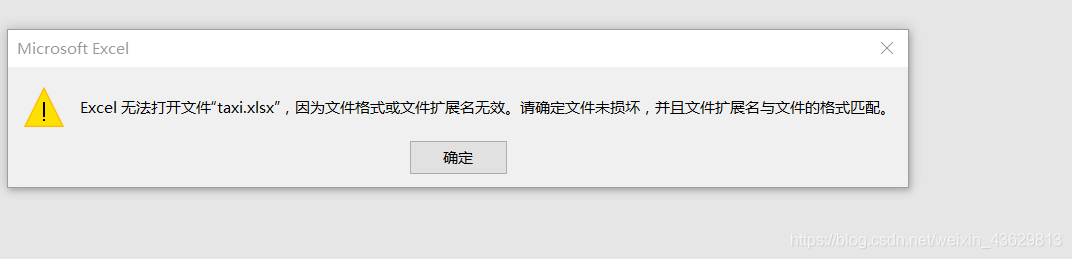
这个数据是我们组找的19年全国大学生数学建模竞赛C题的数据集,是上海市出租车GPS数据集,来自香港科技大学计算机科学与工程系智慧城市研究小组所用的科研数据。 附上网盘链接:https://pan.baidu.com/s/1ERkIz8jD5_TVJULuF361Yw(如果链接打不开大家可以自己找,公开的) 数据集有4316个txt文件,每一个文件是一个司机在上海一天的GPS轨迹和时间点。每列分别是:司机编号,时间,经度,纬度,夹角角度(不是很清楚怎么用),瞬时速度,载客人数。 处理目的:txt太多不好处理,所以想用python将所有txt合到一起,成一个excel文件。 首先下载安装xlrd和xlwt这两个库。 pip install xlwt因为python不熟,写的时候出现了很多bug,比如跑完只有最后一行(好智障的问题,原来是我把建文件的语句写到了循环里面,难受死了),后来每次记录了每个文件的行数,保证率不会覆盖。 这个方法是一个方格一个方格的写进去的,所以读取的txt的一行要存成一个list,用下标定位。 import os import xlwt def eachFile(filepath): pathDir = os.listdir(filepath) # 遍历文件夹中的text return pathDir def readfile(name): fopen = open(name, 'r') cou = 0 for lines in fopen.readlines(): # 按行读取text中的内容 cou = cou + 1 lines = lines.replace("\n", "").split(",")#分割一下 lines_l = list(lines)#每一行都是一个list了 # print(lines_l) fopen.close() return cou filePath = "G:\\桌面\\Taxi"#装txt的文件夹的路径 pathDir = eachFile(filePath) ch = [] le = [] le.append(0) for allDir in pathDir: # child = os.path.join('%s%s' % (filepath, allDir)) child = "G:\\桌面\\Taxi" + '\\' + allDir ch.append(child) readfile(child) le.append(readfile(child)) #用le记录一个txt有多少行,方便下一个文件读取的时候不会在写入时覆盖 for i in range(1, len(le)): le[i] = le[i] + le[i - 1] # print(le) file = xlwt.Workbook(encoding='utf-8') # 新建sheet sheet = file.add_sheet('taxi') for i in range(len(ch)): k = le[i] + 1 print(k) with open(ch[i]) as f1: print(ch[i]) for lines in f1.readlines(): lines = lines.replace("\n", "").split(",") lines_l = list(lines))#每一行都是一个list i = 0 for line in lines_l: sheet.write(k, i, line)#一个一个写 i = i + 1 k = k + 1 f1.close() file.save("G:\\桌面\\taxi.xls")#生成文件的路径,一定要记得save 使用openpyxl库读写excelxlrd和xlwt处理的是xls文件,单个sheet最大行数是65535。我想处理更多数据,网上查到了使用openpyxl函数,最大行数达到1048576。 -----然而我天真的想用这个处理六百万的数据集,跑了几个小时后,文件是生成了,打不开!!如果数据量超过65535就会遇到:ValueError: row index was 65536, not allowed by .xls format最终还是只能存65535行,打开会显示下面的错误。
不过我存了八万多行,虽然还是显示文件损坏,但是可以恢复,数据量再多就不一定行了,修复也打不开,或者乱码,暂时未解决这个问题。 恢复文件方法:打开Excel,文件->打开->浏览->选打开并修复->修复
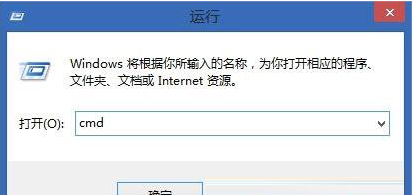
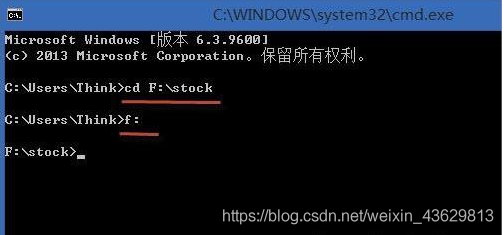
首先需要下载并导入 import openpyxl pip install openpyxl import os import openpyxl as xl def eachFile(filepath): pathDir =os.listdir(filepath) #遍历文件夹中的text return pathDir def readfile(name): fopen=open(name, 'r') cou=0 for lines in fopen.readlines(): #按行读取text中的内容 cou=cou+1 lines = lines.replace("\n", "").split(",") lines_l = list(lines) #print(lines_l) fopen.close() return cou filePath = "G:\\桌面\\t_2" pathDir = eachFile(filePath) ch = [] for allDir in pathDir: # child = os.path.join('%s%s' % (filepath, allDir)) child = "G:\\桌面\\t_2" + '\\' + allDir ch.append(child) readfile(child) wb = xl.Workbook() ws = wb.active ws.title = "sheet" for i in range(len(ch)): with open(ch[i]) as f1: print(ch[i]) for lines in f1.readlines(): lines = lines.replace("\n", "").split(",") lines_l = list(lines) ws.append(lines_l)#直接写一行了,比上一个方法简单 f1.close() wb.save("G:\\桌面\\t_2.xlsx")#这个xlsx跟xls都是excel文件,这个比较新,适用与2013以后版本 最简单的批量合并txt(适用海量数据)前面的方法我还是不能把我的4千多个txt合到一起,失败的尝试,但是练习了一下python,发现这个方法过后觉得真是,太简便了,怎么不早点找到。 就不自己操作截图了,借用百度知道的图片文字: win10批量合并办法:1、想要进行批量合并首先要将合并的txt文件移动到同一文件夹下,文件名要有顺序,我们善用批量改名功能。 2、进入桌面,按下“win + R”快捷键点击运行窗口,写入“cmd”并打开确定点击命令提示符。
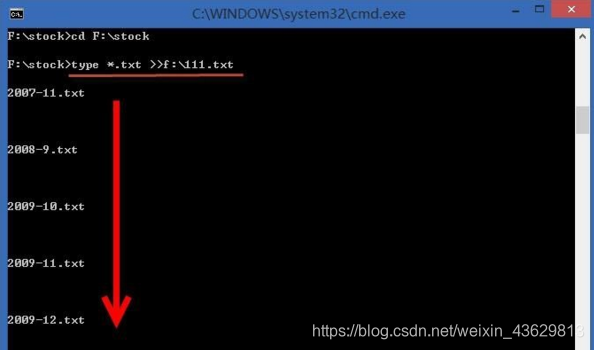
3、进入命令提示符窗口后,使用“cd 文件路径”命令进入需要合并的txt文件的目录,小编这里合并的文件是在“F:\stock”目录下。
4、进入目录后,写入“type *.txt >>f:\111.txt”,按下回车,以后会将当前目录下的所有txt文件的内容按照序号顺序合并到到“f:\111.txt”中。
完成了,所有的txt合到了一个txt里面,当然是无法直接打开的,现在可以导入到Mysql里,进行数据处理了(是有六百多万条的样子)~ 参考:https://www.cnblogs.com/shaosks/p/6098282.html |


【本文地址】